Set up cluster : Spark 1.3.1 en Ubuntu 14.04
Set up cluster manually: Spark 1.3.1 en Ubuntu 14.04
Introduction
When the cluster is running let configure Spark 1.3.1 and assuming Anaconda install to provide numpy.
Set up password-less SSH
Contact each node:
ssh -i /home/raf/Documents/Cloud/rvf_keele_cloud.pem ubuntu@10.8.3.127
ssh -i /home/raf/Documents/Cloud/rvf_keele_cloud.pem ubuntu@10.8.3.128
In the master
ubuntu@master:~$ ssh-keygen -t rsa -P ""
ubuntu@master:~$ cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
chmod 644 $HOME/.ssh/authorized_keys
ubuntu@master:~$ ssh localhost
ubuntu@master:~$ cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
chmod 644 $HOME/.ssh/authorized_keys
ubuntu@master:~$ ssh localhost
with $HOME = /home/ubuntu
On workers:
copy ~/.ssh/id_dsa.pub from your master to the worker, then use:
cat /home/ubuntu/.ssh/id_rsa.pub >> /home/ubuntu/.ssh/authorized_keys
chmod 644 /home/ubuntu/.ssh/authorized_keys
References:
http://stackoverflow.com/questions/31899837/how-to-start-apache-spark-slave-instance-on-a-standalone-environment
With Maven
Configuration file: conf/slaves file on your master
We need to add hostname to /etc/host
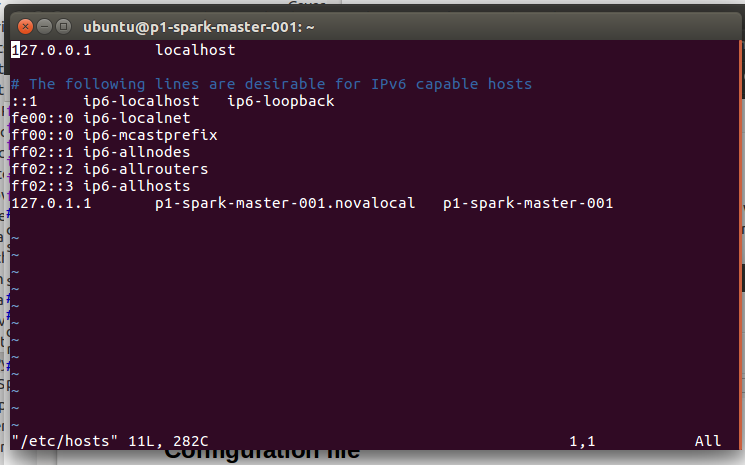
- sudo vim /etc/hosts
- Add Full Qualified HostName (FQHN) and Hostname (to search for it command “ “hostname -f”)

Start Master and Workers
run sbin/start-all.sh
the cluster manager’s web UI should appear at
http://masternode:8080 and show all your workers.
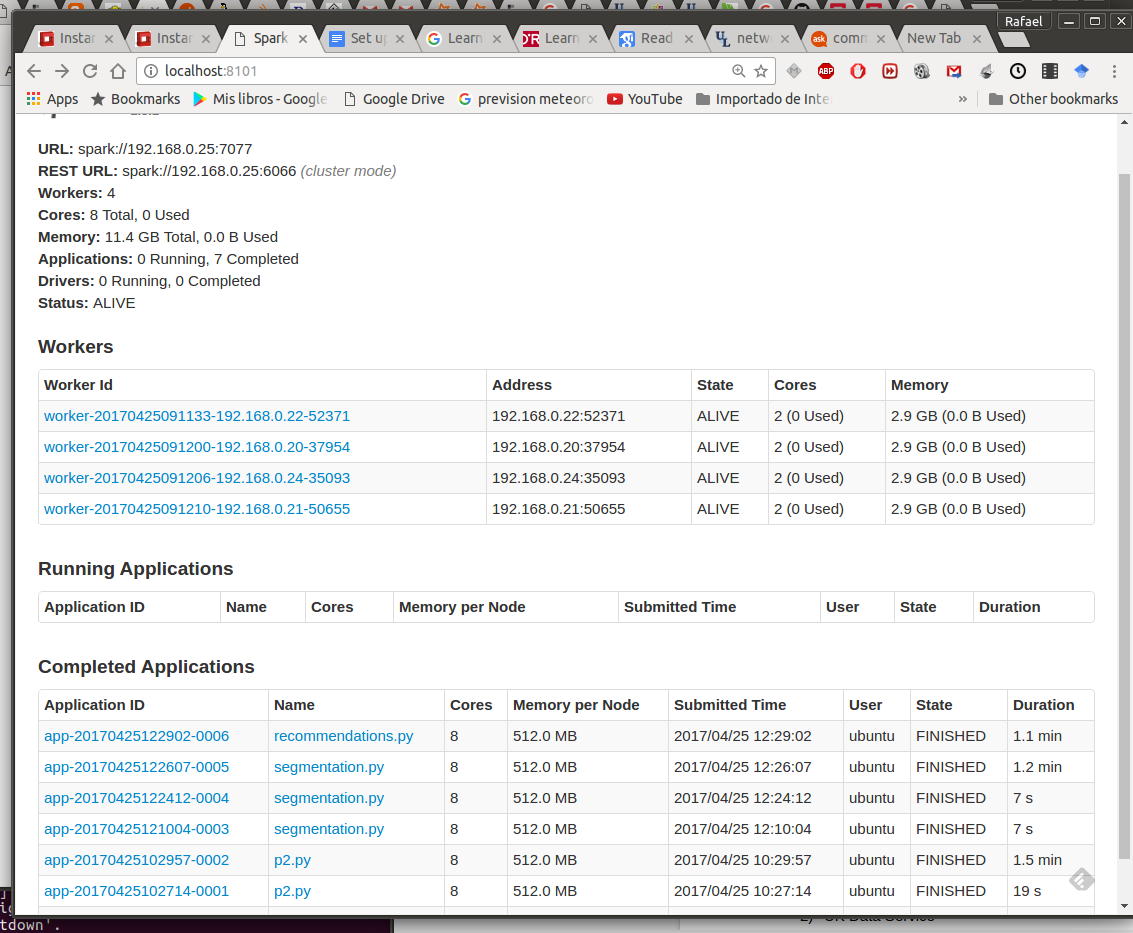
Start Master and Workers by Hand
Run some commands in the Master and in the Workers:
Master
cd /opt/spark/bin/
./spark-class org.apache.spark.deploy.master.Master
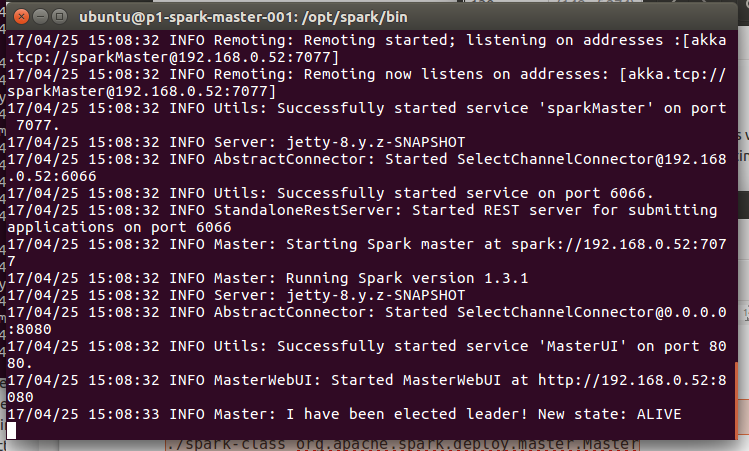
Now you can check those urls:
192.162.0.52:7077 where you should send the jobs and 192.168.0.52:8080 the MasterUI.
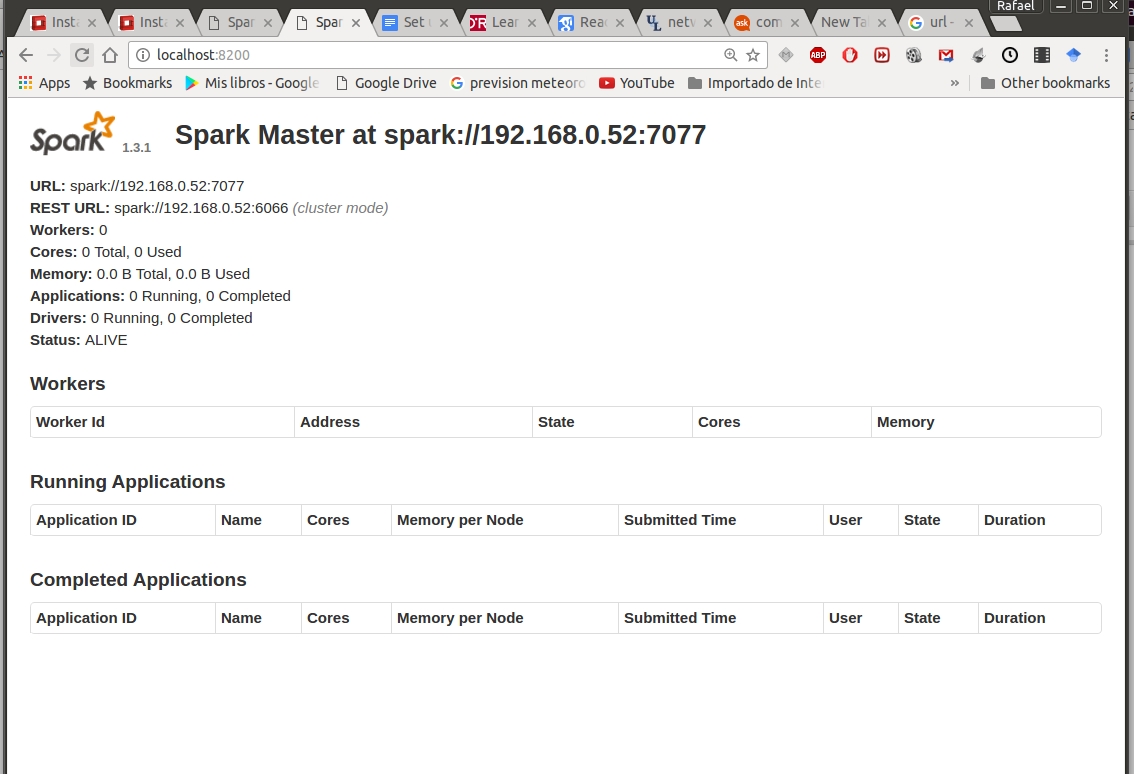
I am going to visit the last one:
Remember the port should be open. As you remember 192.168.0.52 is the internal IP of my master. Tunneling:
ssh -i /home/raf/Documents/Cloud/rvf_keele_cloud.pem -L 8200:localhost:8080 ubuntu@10.8.3.127
Now you can check in the browser: http://localhost:8200/
Workers
cd /opt/spark/bin/
./spark-class org.apache.spark.deploy.worker.Worker spark://192.168.0.52:7077
Now we can see in the browser the inclusion of the new worker:

To submit a job
You have to have a copy of all files in the some location in master and all workers. I have copied a folder with data and a python script in /opt/spark/bin:
cd /opt/spark/bin
./spark-submit --master spark://192.168.0.52:7077 paper_cluster_spark_to_run/recommendations.py
To run it you have to open another ssh: ssh -i /home/raf/Documents/Cloud/rvf_keele_cloud.pem ubuntu@10.8.3.127
References
- To set up everything commands: https://gist.github.com/samklr/75486c2d9e31c5998443
- Karau, H., Konwinski, A., Wendell, P., & Zaharia, M. (2015). Learning spark: lightning-fast big data analysis. " O'Reilly Media, Inc.".


Comentarios
Publicar un comentario